La serie di articoli di R’s Geek Ideal copre una serie di punti chiave sulle idee, l’utilizzo, gli strumenti, le innovazioni di R, ecc. e utilizza il mio apprendimento e la mia esperienza personali per spiegare la potenza di R.
Come linguaggio statistico, il linguaggio R ha sempre brillato in campi di nicchia. Fino all’esplosione dei big data, il linguaggio R è diventato uno strumento importante per l’analisi dei dati. Man mano che sempre più persone con un background in ingegneria si uniscono, la comunità del linguaggio R è in rapida espansione e crescita. Ora non solo il campo delle statistiche, ma anche l’istruzione, le banche, l’e-commerce, Internet… utilizzano tutti il linguaggio R.
Per diventare dei geek ideali, non possiamo fermarci alla grammatica. Dobbiamo padroneggiare una solida conoscenza della matematica, della probabilità e della statistica. Dobbiamo anche avere uno spirito innovativo e utilizzare il linguaggio R in diversi ambiti. Muoviamoci insieme e diamo inizio all’ideale geek di R.
Informazioni sull’autore
- Zhang Dan, analista di dati/programmatore/Quant: R,Java,Nodejs
- Blog: http://fens.me
- E-mail: bsspirit@gmail.com
Si prega di indicare la fonte in caso di ristampa:
Prefazione
L’analisi delle serie temporali è un ramo importante dell’analisi statistica. Molti dati della nostra vita quotidiana sono dati di serie temporali, che contengono almeno un elemento temporale e un valore dei dati. Se riusciamo a osservare bene i dati delle serie temporali, questi possono svolgere un ruolo molto importante nella nostra comprensione dei dati.
timetk è un pacchetto molto conveniente per osservare i dati delle serie temporali, permettendoci di comprendere rapidamente i dati da più angolazioni.
Sommario
- viene introdotto il pacchetto timetk
- Installazione di timetk
- La funzione principale di timetk
- Visualizzazione: grafico delle serie temporali di base
- Visualizzazione: raggruppamento di serie temporali
- Visualizzazione: binning delle serie temporali
- Visualizzazione: regressione delle serie temporali
- Visualizzazione: rilevamento di anomalie nelle serie temporali
- Visualizzazione: scomposizione stagionale delle serie temporali
- Visualizzazione: ricampionamento delle serie temporali
1. Il pacchetto timetk è un’introduzione
timetk è un toolkit per l’elaborazione di serie temporali in linguaggio R, che può facilmente realizzare la visualizzazione, l’organizzazione e l’ingegnerizzazione delle funzionalità dei dati delle serie temporali per la previsione e la modellazione dell’apprendimento automatico. Integra ed estende la funzionalità delle serie temporali da pacchetti tra cui dplyr, stats, xts, previsione, slider, padr, ricette e rsample. Timetk è un potente pacchetto, parte dell’ecosistema modeltime, per l’analisi e la previsione delle serie temporali.
Sito ufficiale: https://business-science.github.io/timetk/
Il pacchetto timetk consente agli utenti di elaborare oggetti di serie temporali in modo più conveniente nel linguaggio R. Il toolkit fornisce funzionalità per l’ispezione e l’elaborazione di indici basati sul tempo, estendendo le funzionalità temporali per l’esplorazione dei dati e l’apprendimento automatico e la conversione tra diverse categorie di serie temporali.
I principali vantaggi sono i seguenti:
- Estrazione dell’indice: estrae l’indice delle serie temporali da qualsiasi oggetto della serie temporale.
- Comprensione delle serie temporali: genera riepiloghi delle funzionalità e informazioni di riepilogo in base agli indici delle serie temporali.
- Costruisci serie temporali future: crea serie temporali future basate su indici esistenti.
- Conversione tra tipi di tibble basati sul tempo e tipi di dati di serie temporali tradizionali (xts, zoo, zooreg, ts): semplifica il processo di conversione e conserva al massimo le informazioni sui dati basati sul tempo durante la conversione in serie temporali regolari (come ts).
2. Installazione di timetk
Installazione del pacchetto timetk. Installare il pacchetto timetk è molto semplice. Può essere completato con 2 istruzioni, installa e carica.
# 安装
> install.packages("timetk")
# 加载
> library(timetk)
3. La funzione principale di timetk
Usando il pacchetto timetk, puoi adattarti a diversi tipi di serie temporali del linguaggio R, come tk_tbl() che si adatta al tipo tibble, tk_zoo() che si adatta al tipo zoo, tk_xts() che si adatta al tipo xts, ecc.
La funzione principale della suite timetk è la funzione di disegno, che supporta 11 effetti di disegno visivo.
- plot_time_series Trama interattiva di una o più serie temporali
- plot_time_series_boxplot Boxplot interattivo delle serie temporali
- plot_time_series_regression Visualizza la formula di regressione lineare delle serie temporali
- plot_anomalies Visualizza valori anomali in una o più serie temporali
- plot_anomalies_cleaned Visualizza i valori anomali (dopo la pulizia) di una o più serie temporali
- plot_anomalies_decomp Visualizza i valori anomali (dopo la scomposizione) in una o più serie temporali
- plot_anomaly_diagnostics Visualizza la diagnosi dei valori anomali per una o più serie temporali
- plot_seasonal_diagnostics Visualizza varie caratteristiche stagionali di una o più serie temporali
- plot_stl_diagnostics Visualizza le caratteristiche di scomposizione STL di una o più serie temporali
- plot_acf_diagnostics Visualizza ACF, PACF e CCF per una o più serie temporali
- plot_time_series_cv_plan Visualizza il piano di ricampionamento delle serie temporali
4. Visualizzazione: diagramma di base delle serie temporali
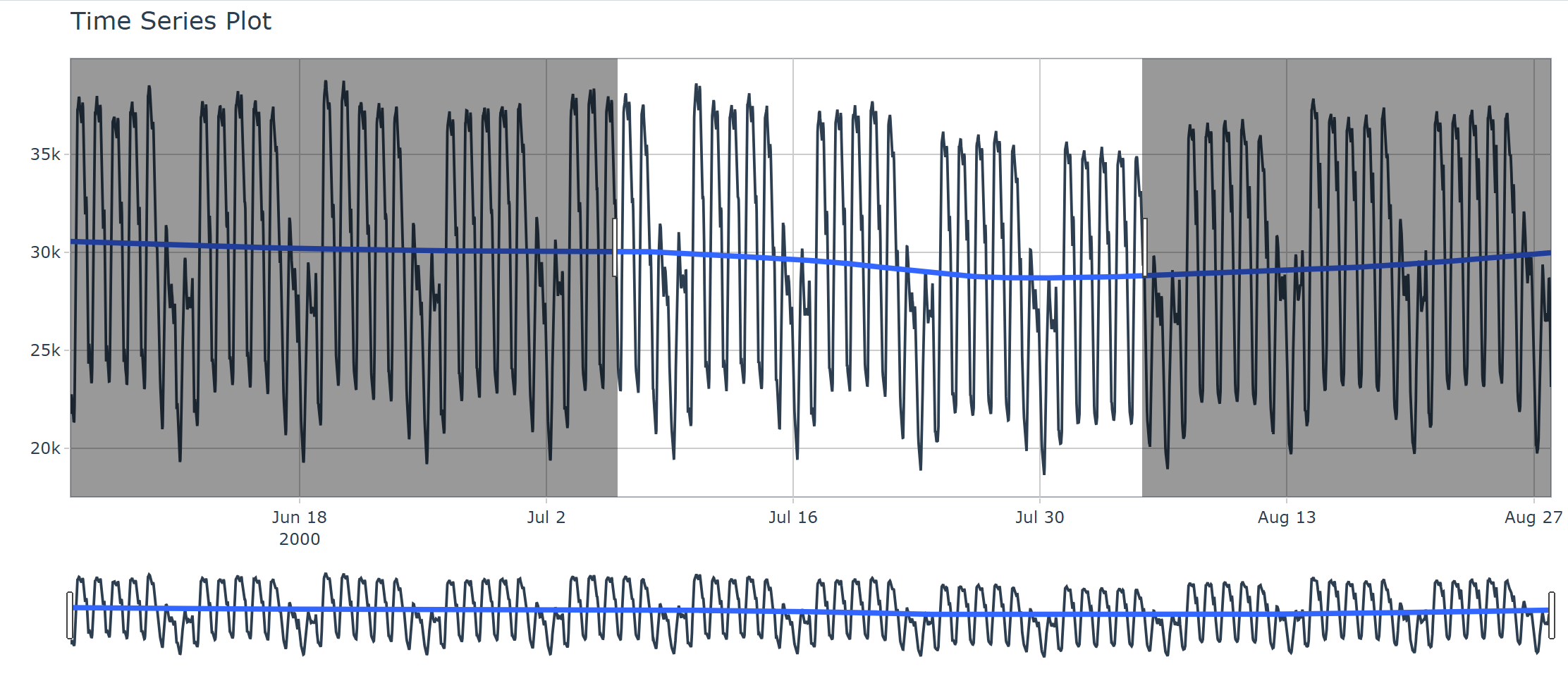
Prendi come esempio il set di dati taylor_30_min fornito con il pacchetto timetk, il set di dati taylor_30_min. Domanda di elettricità ogni mezz’ora in Inghilterra e Galles per il periodo da lunedì 5 giugno 2000 a domenica 27 agosto 2000.
Il set di dati taylor_30_min è di tipo tibble, 4.032 righe × 2 colonne:
- data: data e ora variabili, con un intervallo di 30 minuti
- valore: domanda di energia, in megawatt
Controlla lo stato dei dati
# 查看数据前6条
> head(taylor_30_min)
# A tibble: 6 × 2
date value
1 2000-06-05 00:00:00 22262
2 2000-06-05 00:30:00 21756
3 2000-06-05 01:00:00 22247
4 2000-06-05 01:30:00 22759
5 2000-06-05 02:00:00 22549
6 2000-06-05 02:30:00 22313
# 查看数据2列统计概览
> summary(taylor_30_min)
date value
Min. :2000-06-05 00:00:00 Min. :18640
1st Qu.:2000-06-25 23:52:30 1st Qu.:24272
Median :2000-07-16 23:45:00 Median :29485
Mean :2000-07-16 23:45:00 Mean :29617
3rd Qu.:2000-08-06 23:37:30 3rd Qu.:35132
Max. :2000-08-27 23:30:00 Max. :38777
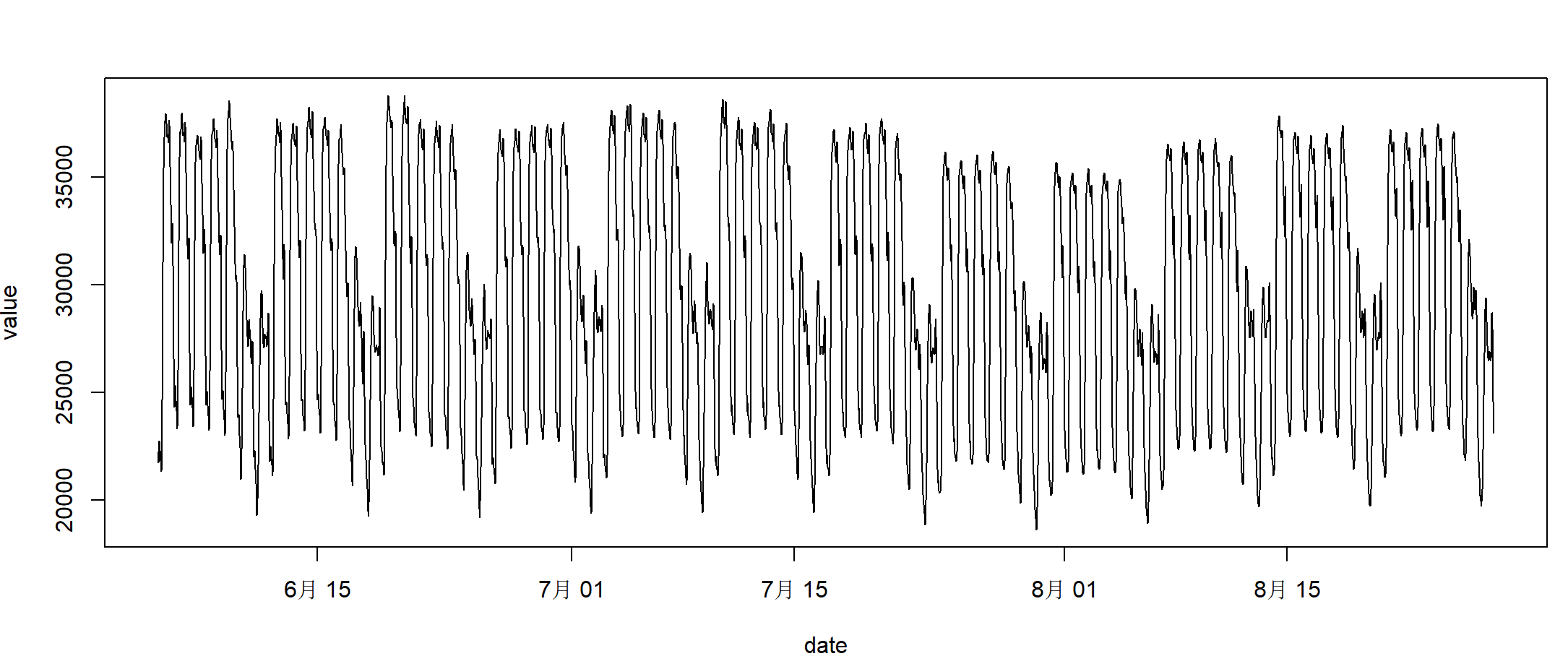
Disegna un grafico basato sui dati e utilizza la funzione di base plot() per disegnare il grafico.
> plot(taylor_30_min,type="l")
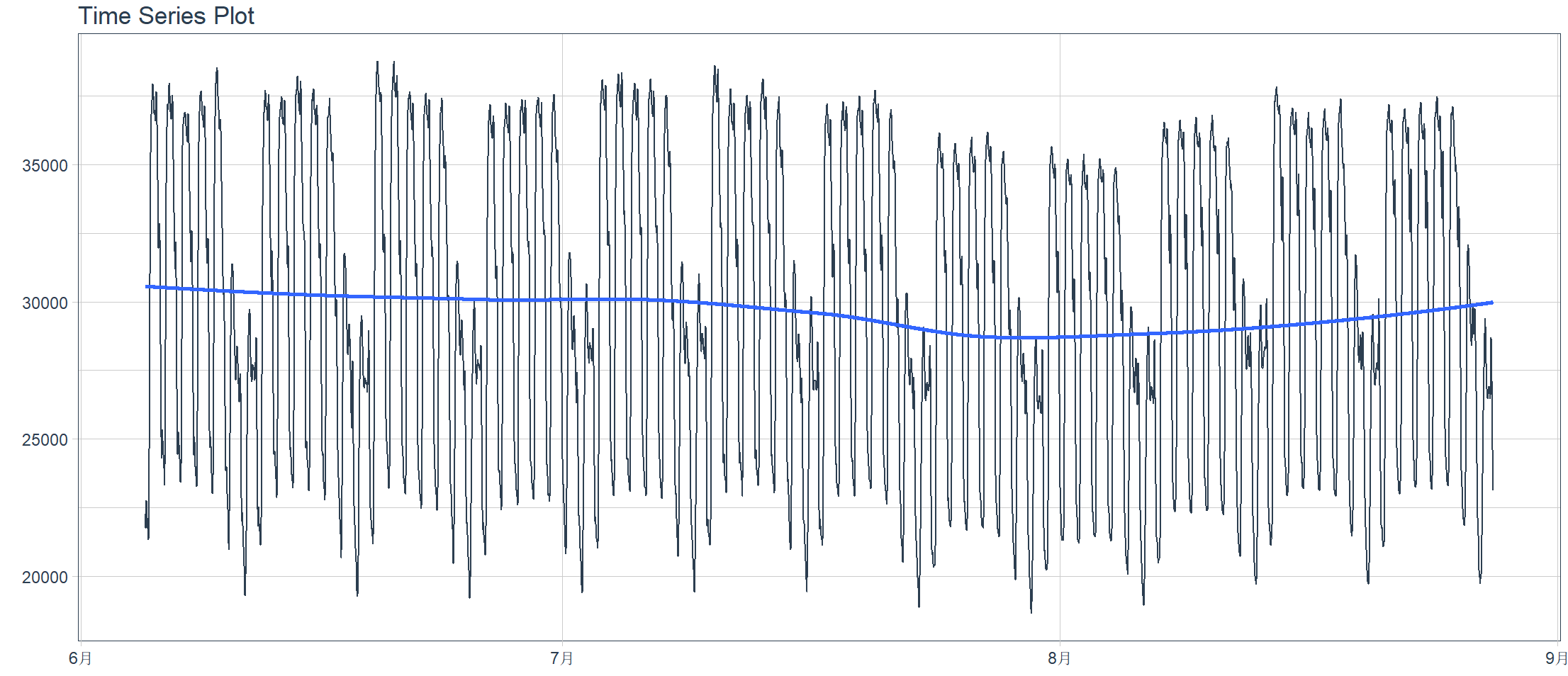
Utilizza timetk per disegnare grafici ed eseguire l’adattamento dei dati
# 加载包
> library(dplyr)
> library(ggplot2)
> library(lubridate)
> library(magrittr)
# 生成基于ggplot2的静态图
> interactive <- FALSE # 画图拟合 > taylor_30_min %>%
+ plot_time_series(date, value,
+ .interactive = interactive,
+ .plotly_slider = TRUE)
Ignoring unknown labels:
• colour : "Legend"
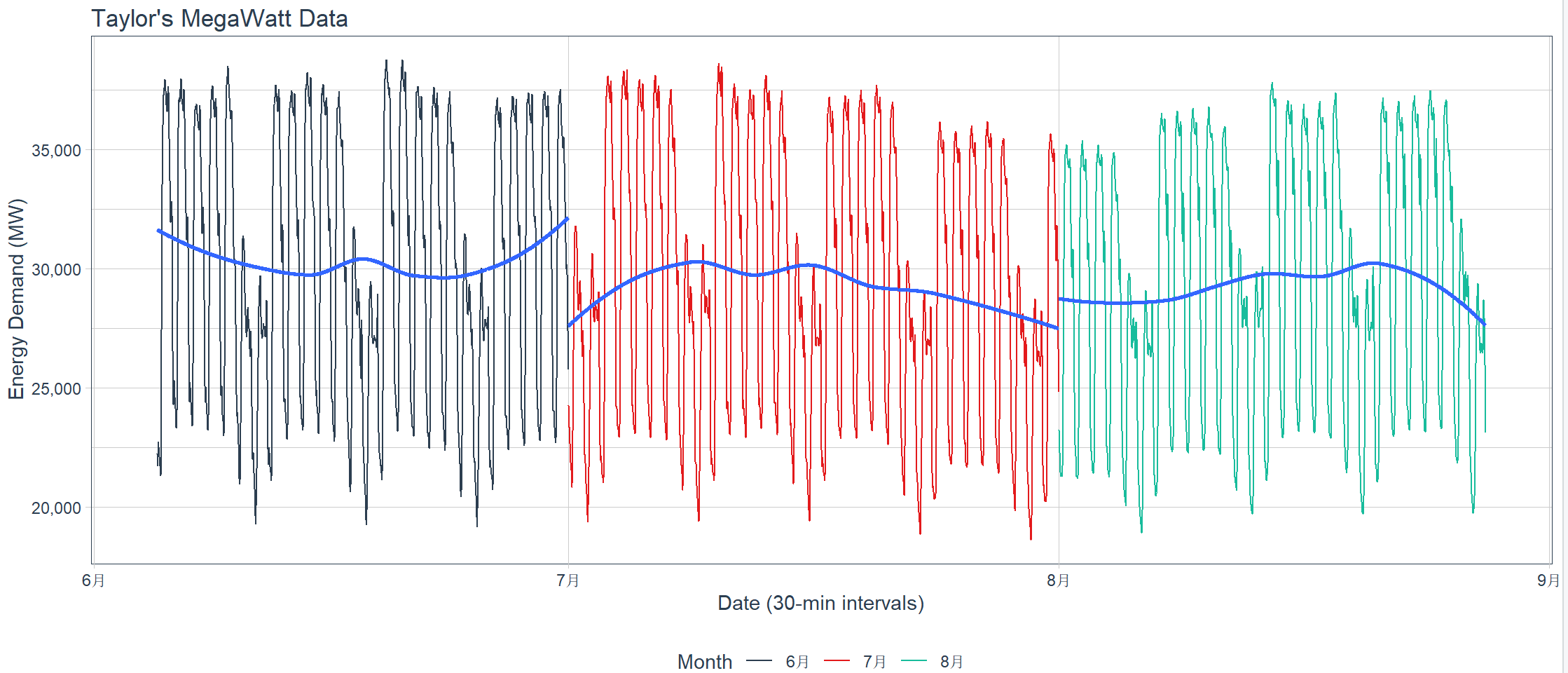
Eseguire la suddivisione e l’adattamento dei dati su base mensile
# 画图拟合
> taylor_30_min %>%
+ plot_time_series(date, value,
+ .color_var = month(date, label = TRUE),
+ .interactive = interactive,
+ .title = "Taylor's MegaWatt Data",
+ .x_lab = "Date (30-min intervals)",
+ .y_lab = "Energy Demand (MW)",
+ .color_lab = "Month") +
+ scale_y_continuous(labels = scales::label_comma())
Utilizza l’output del disegno interattivo, interattivo=TRUE. Può produrre risultati di interazione dinamica basati sulla trama.
> taylor_30_min %>%
+ plot_time_series(date, value,
+ .interactive = TRUE,
+ .plotly_slider = TRUE)
Ignoring unknown labels:
• colour : "Legend"
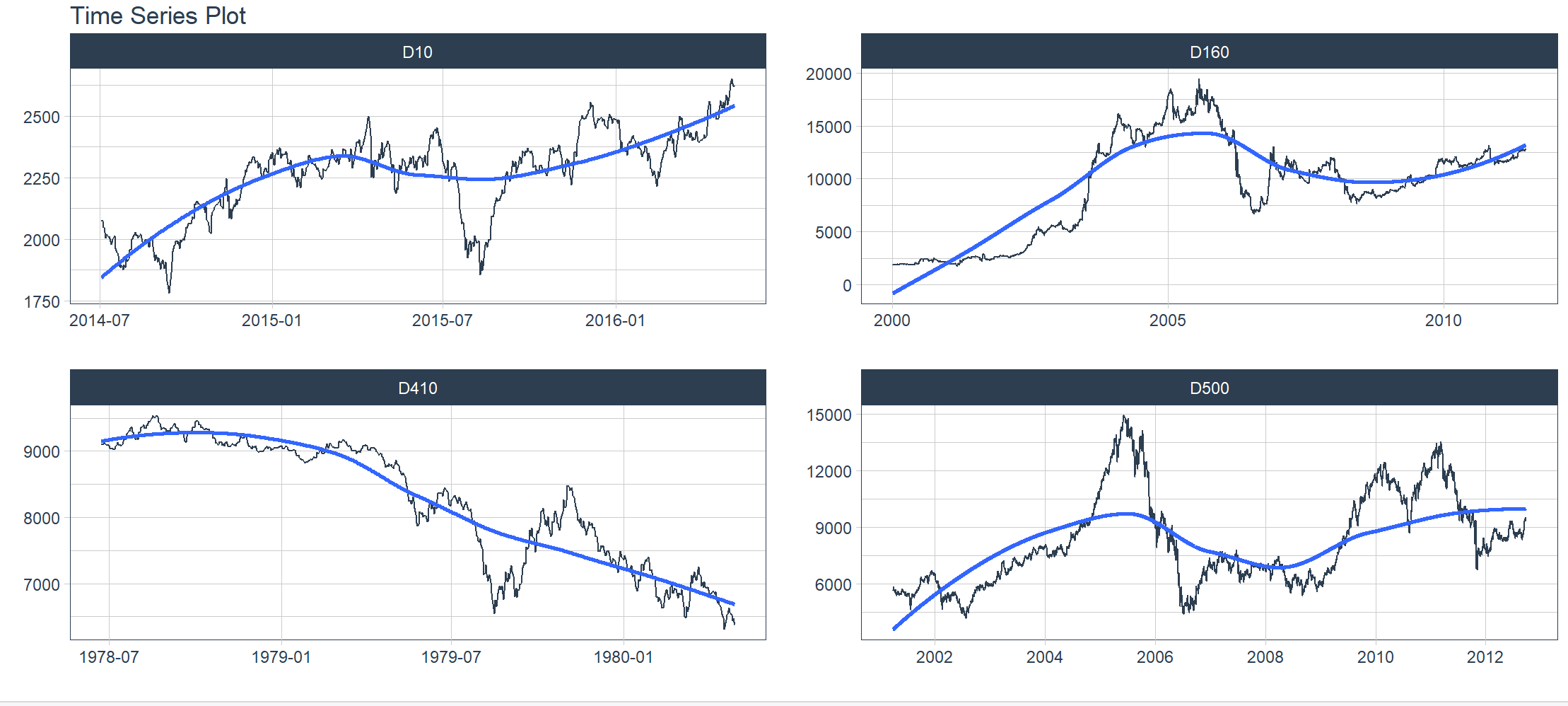
5. Visualizzazione: raggruppamento di serie temporali
1. Visualizzazione del gruppo
Modifichiamo un altro set di dati m4_daily ed effettuiamo un test dimostrativo. Fonte del set di dati m4_daily: competizione M4 (gennaio – maggio 2018), numero totale di sequenze nella competizione completa: 100.000, questo campione: 4 serie temporali giornaliere, numero di righe: 9.743, colonne: id, data, valore.
- id è l’identificatore univoco di ciascuna delle 4 sequenze del tipo di fattore
- data tipo data timestamp giornaliero
- value è un valore numerico corrispondente al timestamp.
Poiché questi dati provengono dalla competizione M4, è probabile che ciascuna serie provenga da un dominio diverso (ad esempio micro, industriale, macro, finanziario, demografico, ecc.) e possa mostrare: tendenze, stagionalità (settimanale, annuale), eteroschedasticità, valori zero o intermittenti, lunghezze diverse (le lunghezze dei dati storici per le serie giornaliere tendono a variare).
# 查看数据集
> head(m4_daily)
# A tibble: 6 × 3
id date value
1 D10 2014-07-03 2076.
2 D10 2014-07-04 2073.
3 D10 2014-07-05 2049.
4 D10 2014-07-06 2049.
5 D10 2014-07-07 2006.
6 D10 2014-07-08 2018.
# 统计概览
> summary(m4_daily)
id date value
D10 : 674 Min. :1978-06-23 Min. : 1735
D160:4197 1st Qu.:2003-01-12 1st Qu.: 5719
D410: 676 Median :2006-05-14 Median : 8253
D500:4196 Mean :2005-02-14 Mean : 8280
3rd Qu.:2009-09-13 3rd Qu.:11219
Max. :2016-05-06 Max. :19433
Visualizzare i dati raggruppati è semplicemente questione di utilizzare group_by() per raggruppare il set di dati prima di passare i dati alla funzione plot_time_series(). I punti chiave sono i seguenti:
- Puoi aggiungere gruppi in due modi: utilizzando group_by() o aggiungendo gruppi tramite il parametro….
- I raggruppamenti vengono quindi convertiti in sfaccettature.
- .facet_ncol = 2 produce un grafico a faccette a due colonne.
- .facet_scales = “free” consente di ridimensionare gli assi xey di ciascun grafico indipendentemente dagli altri grafici.
> m4_daily %>%
+ group_by(id) %>%
+ plot_time_series(date, value,
+ .facet_ncol = 2, .facet_scales = "free",
+ .interactive = interactive)
Ignoring unknown labels:
• colour : "Legend"
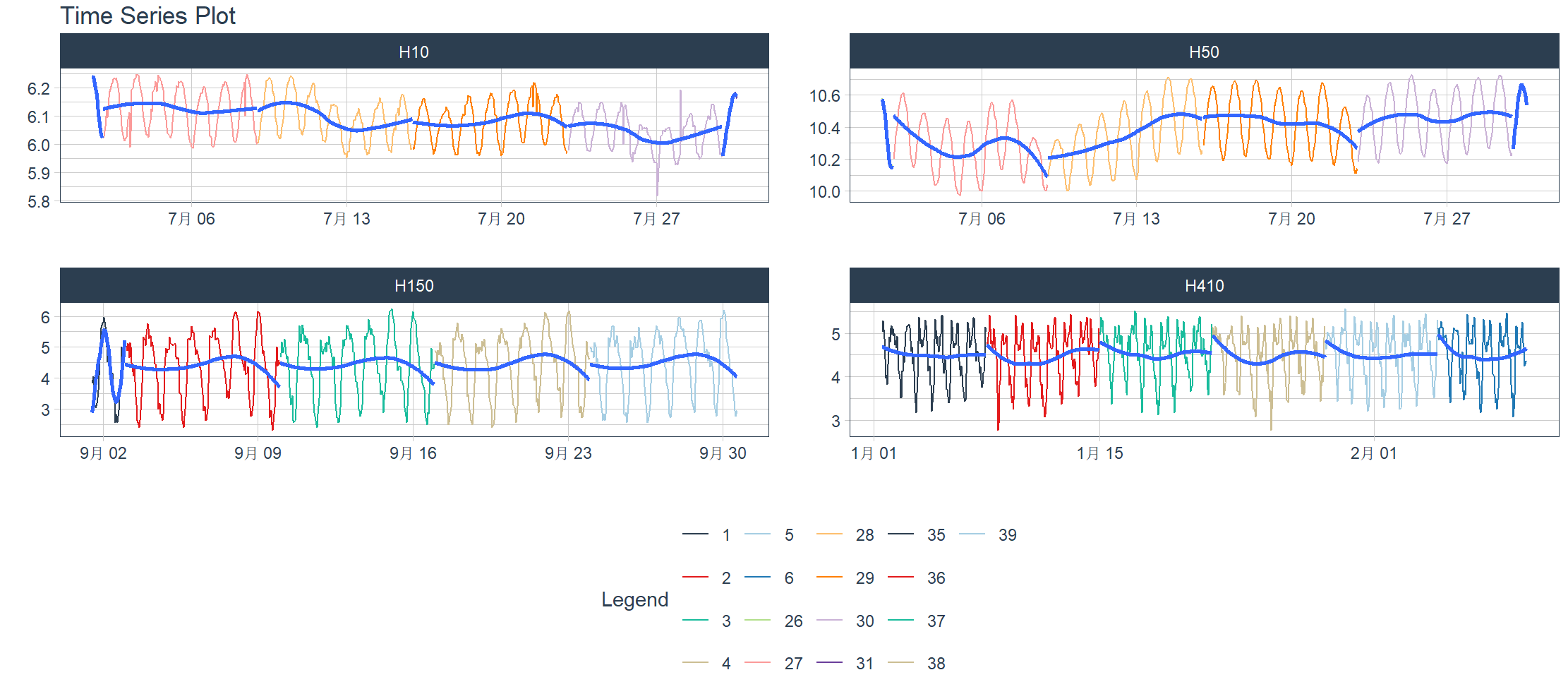
2. Trasformazione logaritmica e sottoraggruppamento
Passiamo a un set di dati orario che contiene più gruppi. Possiamo visualizzare quanto segue. L’intenzione è quella di visualizzare i raggruppamenti in un grafico a faccette evidenziando le finestre settimanali (sottogruppi) nei dati e log() trasformando i valori.
- .value = log(value): applica la trasformazione logaritmica
- .color_var = week(date): Converti la colonna della data nel numero della settimana con lubridate::week(), il colore verrà applicato a ciascun numero della settimana.
Modificato in m4_hourly, il concorso M4 è iniziato il 1 gennaio 2018 e si è concluso il 31 maggio 2018. Il concorso contiene 100.000 set di dati di serie temporali. Questo set di dati contiene un campione di serie temporali orarie di 4 ore per questa competizione.
> m4_hourly %>%
+ group_by(id) %>%
+ plot_time_series(date, log(value), # Apply a Log Transformation
+ .color_var = week(date), # Color applied to Week transformation
+ # Facet formatting
+ .facet_ncol = 2,
+ .facet_scales = "free",
+ .interactive = interactive)
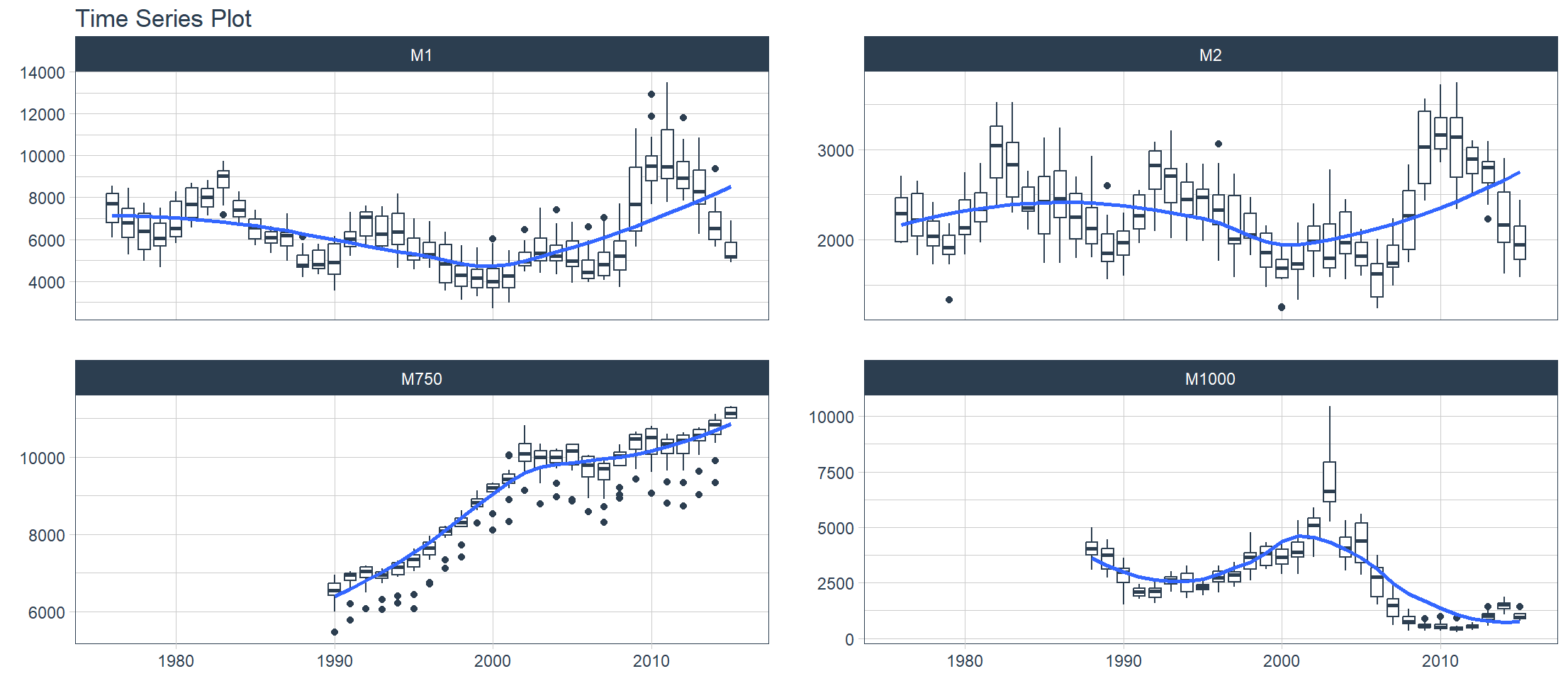
6. Visualizzazione: binning delle serie temporali
La funzione plot_time_series_boxplot() può essere utilizzata per disegnare boxplot. I boxplot utilizzano l’aggregazione, che è un parametro di categorizzazione definito dal parametro .period.
Modificato in m4_monthly, il concorso M4 inizia il 1 gennaio 2018 e termina il 31 maggio 2018. Il concorso contiene 100.000 set di dati di serie temporali. Questo set di dati contiene 4 campioni di serie temporali mensili della concorrenza.
> m4_monthly %>%
+ group_by(id) %>%
+ plot_time_series_boxplot(
+ date, value,
+ .period = "1 year",
+ .facet_ncol = 2,
+ .interactive = FALSE)
Ignoring unknown labels:
• colour : "Legend"
7. Visualizzazione: regressione delle serie temporali
Utilizza la funzione di grafico di regressione delle serie temporali plot_time_series_regression() per valutare rapidamente le caratteristiche chiave associate a una serie temporale. Internamente questa funzione passa una formula alla funzione stats::lm(). Impostando show_summary = TRUE, è possibile visualizzare le informazioni di riepilogo della regressione lineare.
Passa ai dati m4_monthly per disegnare immagini
> m4_monthly %>%
+ group_by(id) %>%
+ plot_time_series_regression(
+ .date_var = date,
+ .formula = log(value) ~ as.numeric(date) + month(date, label = TRUE),
+ .facet_ncol = 2,
+ .interactive = FALSE,
+ .show_summary = FALSE
+ )
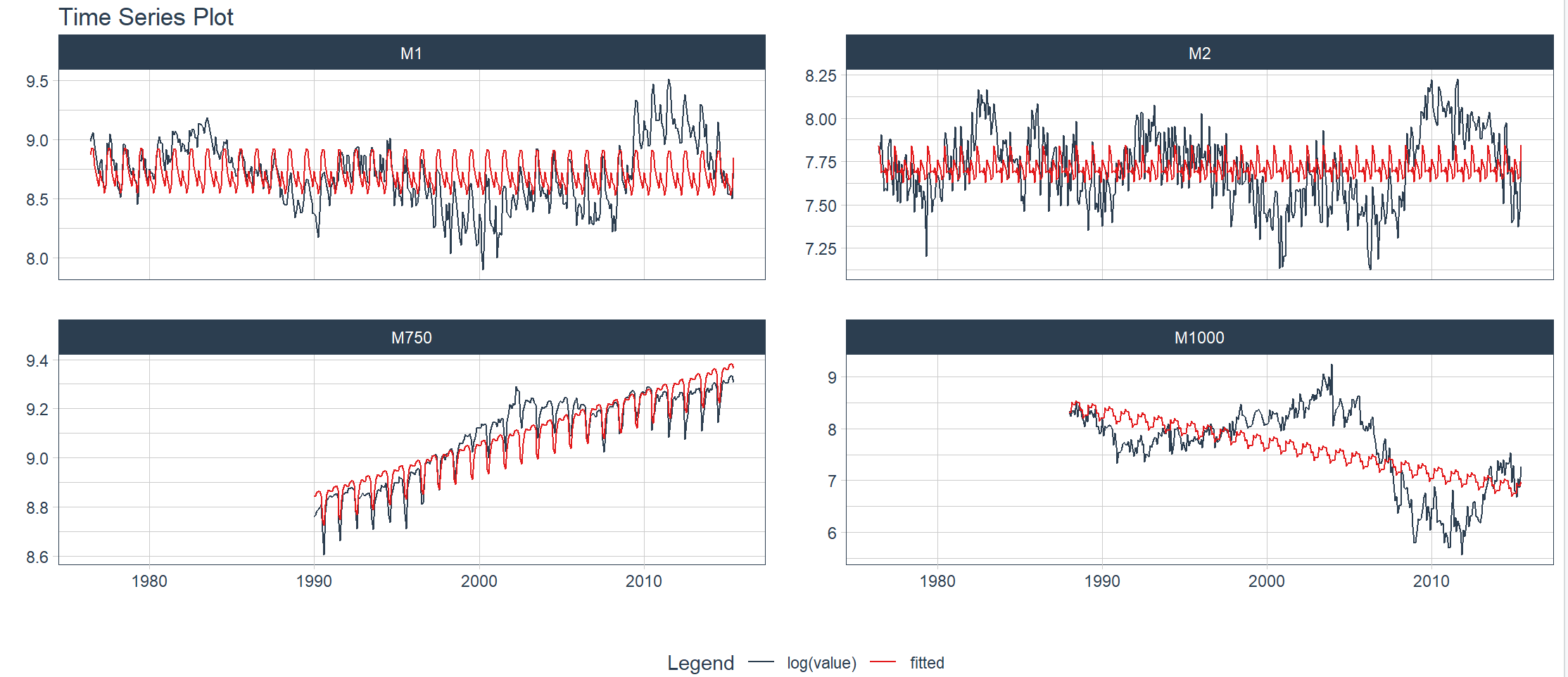
8. Visualizzazione: rilevamento di anomalie nelle serie temporali
Utilizza il set di dati walmart_sales_weekly per visualizzare i valori anomali in una o più serie temporali.
walmart_sales_weekly data set, Walmart Recruitment – Store Sales Forecast” utilizza i dati di vendita al dettaglio, coinvolgendo una combinazione di negozi e reparti interni al negozio. Il concorso è iniziato il 20 febbraio 2014 e si è concluso il 5 maggio 2014.
Visualizza il profilo walmart_sales_weekly
# 查看数据
> head(walmart_sales_weekly)
# A tibble: 6 × 17
id Store Dept Date Weekly_Sales IsHoliday Type Size Temperature Fuel_Price MarkDown1 MarkDown2 MarkDown3 MarkDown4
1 1_1 1 1 2010-02-05 24924. FALSE A 151315 42.3 2.57 NA NA NA NA
2 1_1 1 1 2010-02-12 46039. TRUE A 151315 38.5 2.55 NA NA NA NA
3 1_1 1 1 2010-02-19 41596. FALSE A 151315 39.9 2.51 NA NA NA NA
4 1_1 1 1 2010-02-26 19404. FALSE A 151315 46.6 2.56 NA NA NA NA
5 1_1 1 1 2010-03-05 21828. FALSE A 151315 46.5 2.62 NA NA NA NA
6 1_1 1 1 2010-03-12 21043. FALSE A 151315 57.8 2.67 NA NA NA NA
# ℹ 3 more variables: MarkDown5 , CPI , Unemployment
# 统计概览
> summary(walmart_sales_weekly)
id Store Dept Date Weekly_Sales IsHoliday Type
1_1 :143 Min. :1 Min. : 1.00 Min. :2010-02-05 Min. : 6166 Mode :logical Length:1001
1_3 :143 1st Qu.:1 1st Qu.: 3.00 1st Qu.:2010-10-08 1st Qu.: 28257 FALSE:931 Class :character
1_8 :143 Median :1 Median :13.00 Median :2011-06-17 Median : 39886 TRUE :70 Mode :character
1_13 :143 Mean :1 Mean :35.86 Mean :2011-06-17 Mean : 54646
1_38 :143 3rd Qu.:1 3rd Qu.:93.00 3rd Qu.:2012-02-24 3rd Qu.: 77944
1_93 :143 Max. :1 Max. :95.00 Max. :2012-10-26 Max. :148798
(Other):143
Size Temperature Fuel_Price MarkDown1 MarkDown2 MarkDown3 MarkDown4
Min. :151315 Min. :35.40 Min. :2.514 Min. : 410.3 Min. : 0.50 Min. : 0.25 Min. : 8.0
1st Qu.:151315 1st Qu.:57.79 1st Qu.:2.759 1st Qu.: 4039.4 1st Qu.: 40.48 1st Qu.: 6.00 1st Qu.: 577.1
Median :151315 Median :69.64 Median :3.290 Median : 6154.1 Median : 144.87 Median : 25.96 Median : 1822.5
Mean :151315 Mean :68.31 Mean :3.220 Mean : 8090.8 Mean : 2941.32 Mean : 1225.40 Mean : 3746.1
3rd Qu.:151315 3rd Qu.:80.49 3rd Qu.:3.594 3rd Qu.:10122.0 3rd Qu.: 1569.00 3rd Qu.: 101.64 3rd Qu.: 3750.6
Max. :151315 Max. :91.65 Max. :3.907 Max. :34577.1 Max. :46011.38 Max. :55805.51 Max. :32403.9
NA's :644 NA's :707 NA's :651 NA's :644
MarkDown5 CPI Unemployment
Min. : 554.9 Min. :210.3 Min. :6.573
1st Qu.: 3127.9 1st Qu.:211.5 1st Qu.:7.348
Median : 4325.2 Median :215.5 Median :7.787
Mean : 5018.7 Mean :216.0 Mean :7.610
3rd Qu.: 6222.2 3rd Qu.:220.6 3rd Qu.:7.838
Max. :20475.3 Max. :223.4 Max. :8.106
NA's :644
> walmart_sales_weekly %>%
+ filter(id %in% c("1_1", "1_3")) %>%
+ group_by(id) %>%
+ anomalize(Date, Weekly_Sales) %>%
+ plot_anomalies(Date, .facet_ncol = 2, .ribbon_alpha = 0.25, .interactive = FALSE)
frequency = 13 observations per 1 quarter
trend = 52 observations per 1 year
frequency = 13 observations per 1 quarter
trend = 52 observations per 1 year
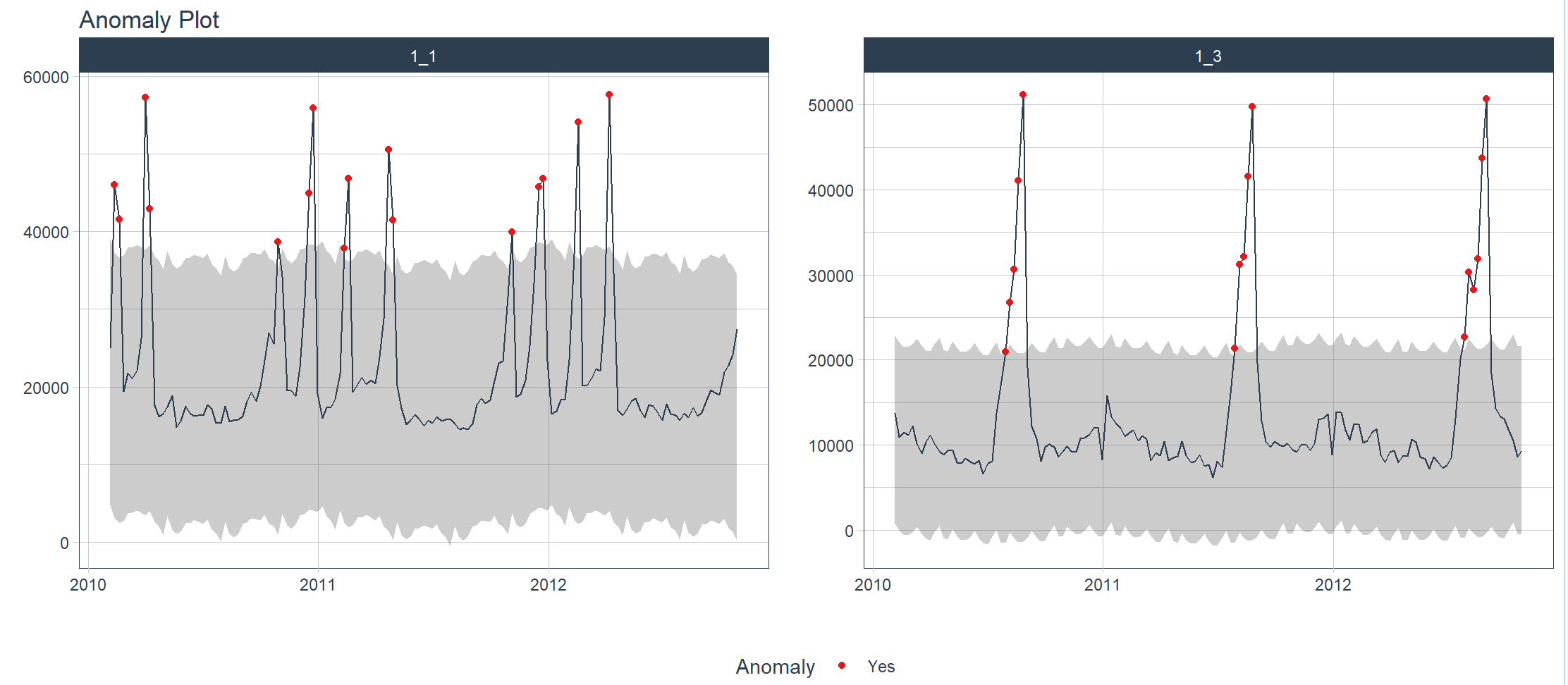
Visualizza i valori anomali in una o più serie temporali e pulisci automaticamente i risultati.
> walmart_sales_weekly %>%
+ filter(id %in% c("1_1", "1_3")) %>%
+ group_by(id) %>%
+ anomalize(Date, Weekly_Sales, .message = FALSE) %>%
+ plot_anomalies_cleaned(Date, .facet_ncol = 2, .interactive = FALSE)
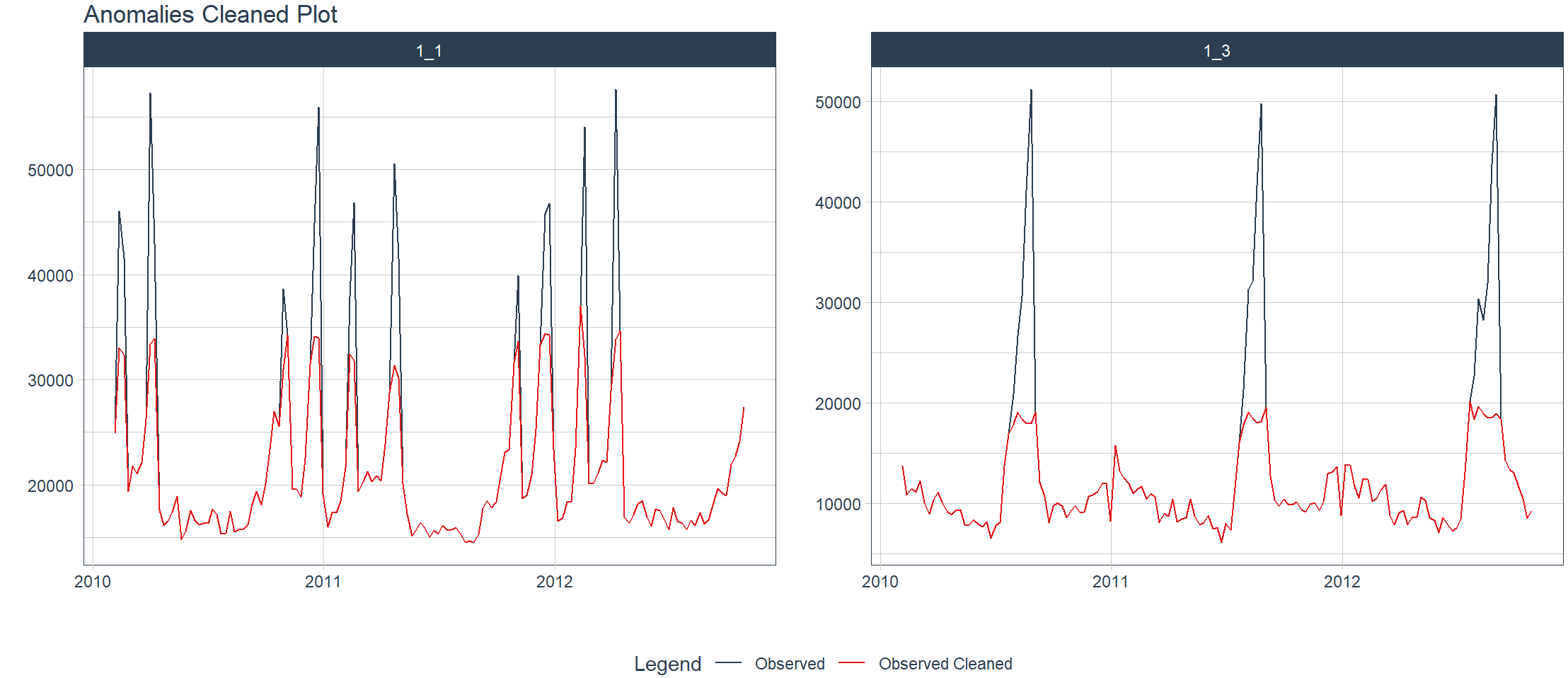
Scomporre i dati in più dimensioni di serie temporali.
> walmart_sales_weekly %>%
+ filter(id %in% c("1_1", "1_3")) %>%
+ group_by(id) %>%
+ anomalize(Date, Weekly_Sales, .message = FALSE) %>%
+ plot_anomalies_decomp(Date, .interactive = FALSE)
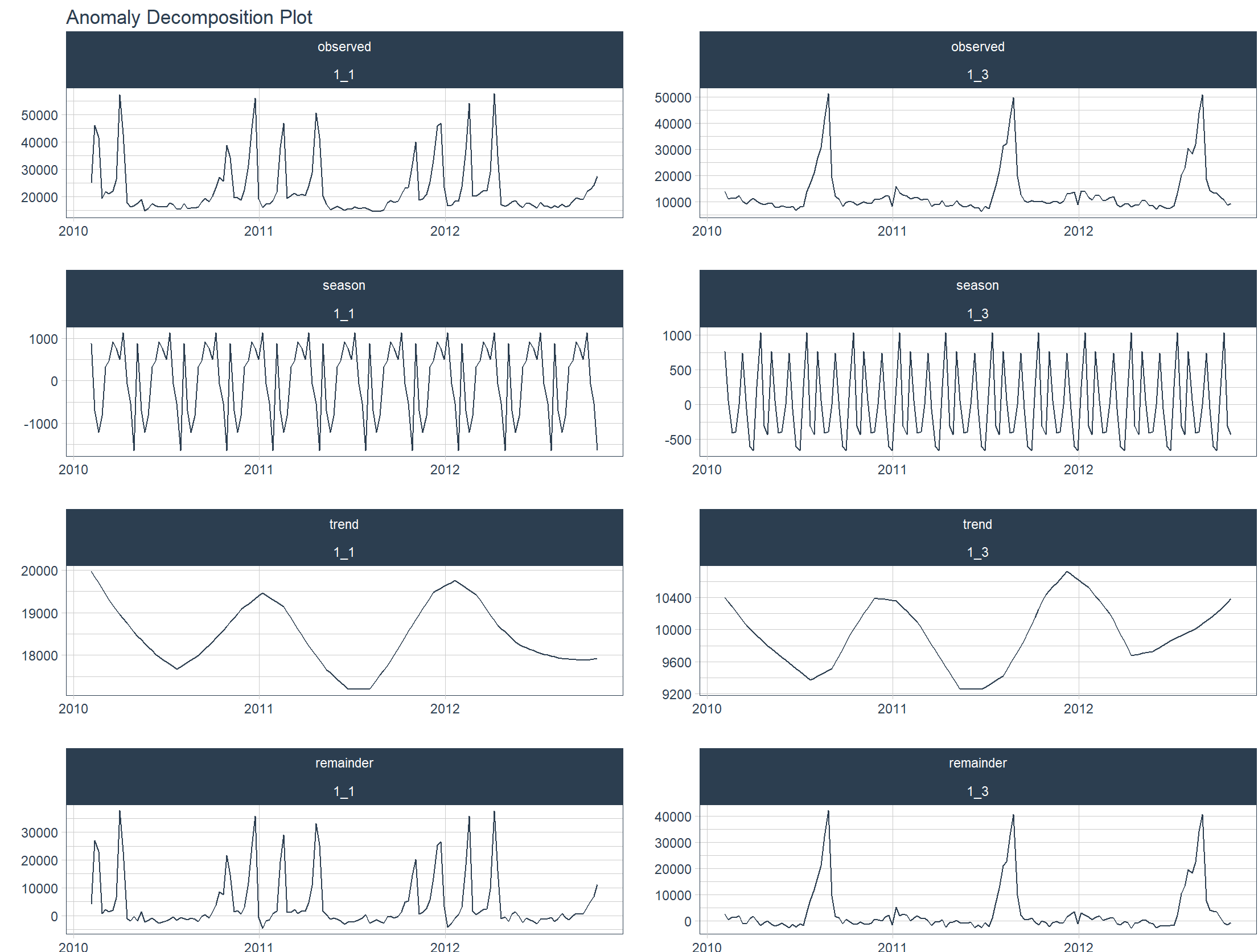
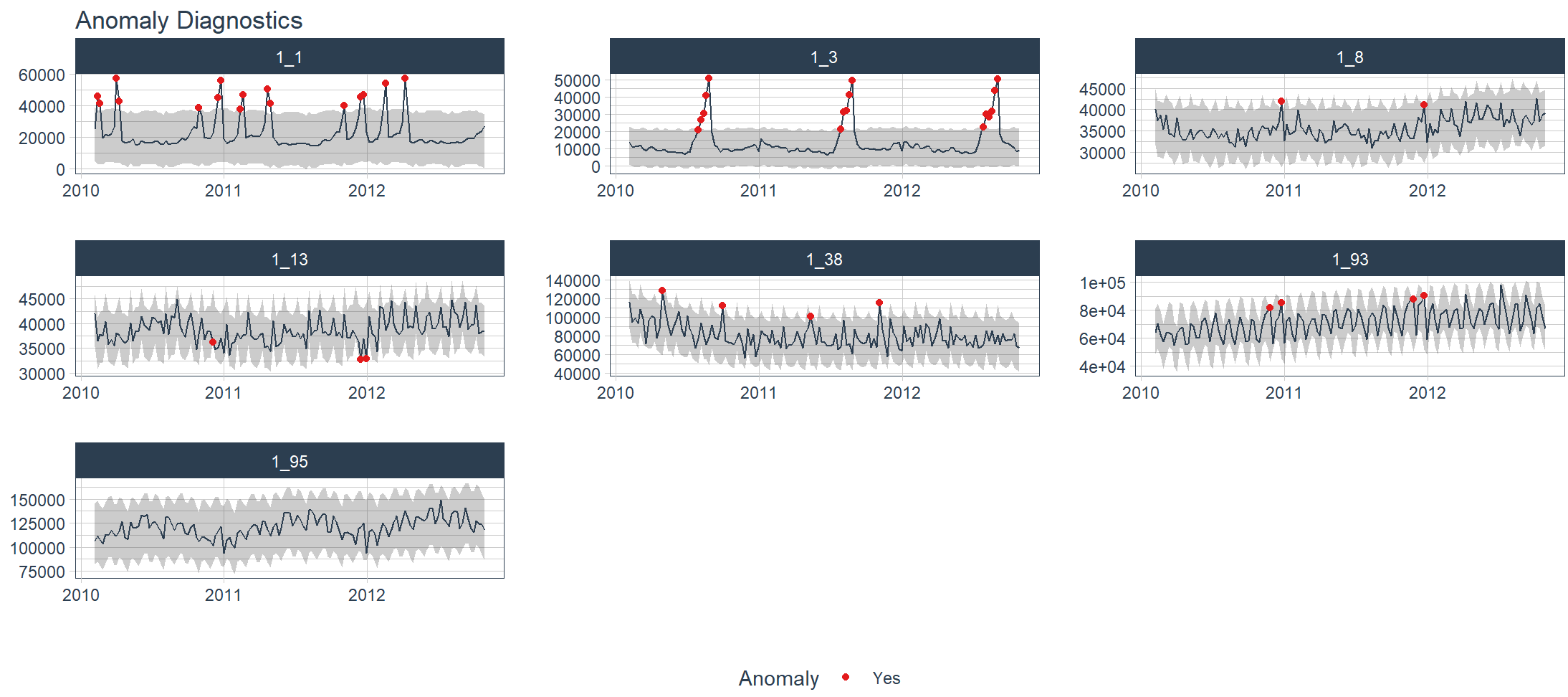
Diagnosticare anomalie nei dati in serie temporali.
> walmart_sales_weekly %>%
+ group_by(id) %>%
+ plot_anomaly_diagnostics(Date, Weekly_Sales,
+ .message = FALSE,
+ .facet_ncol = 3,
+ .ribbon_alpha = 0.25,
+ .interactive = FALSE)
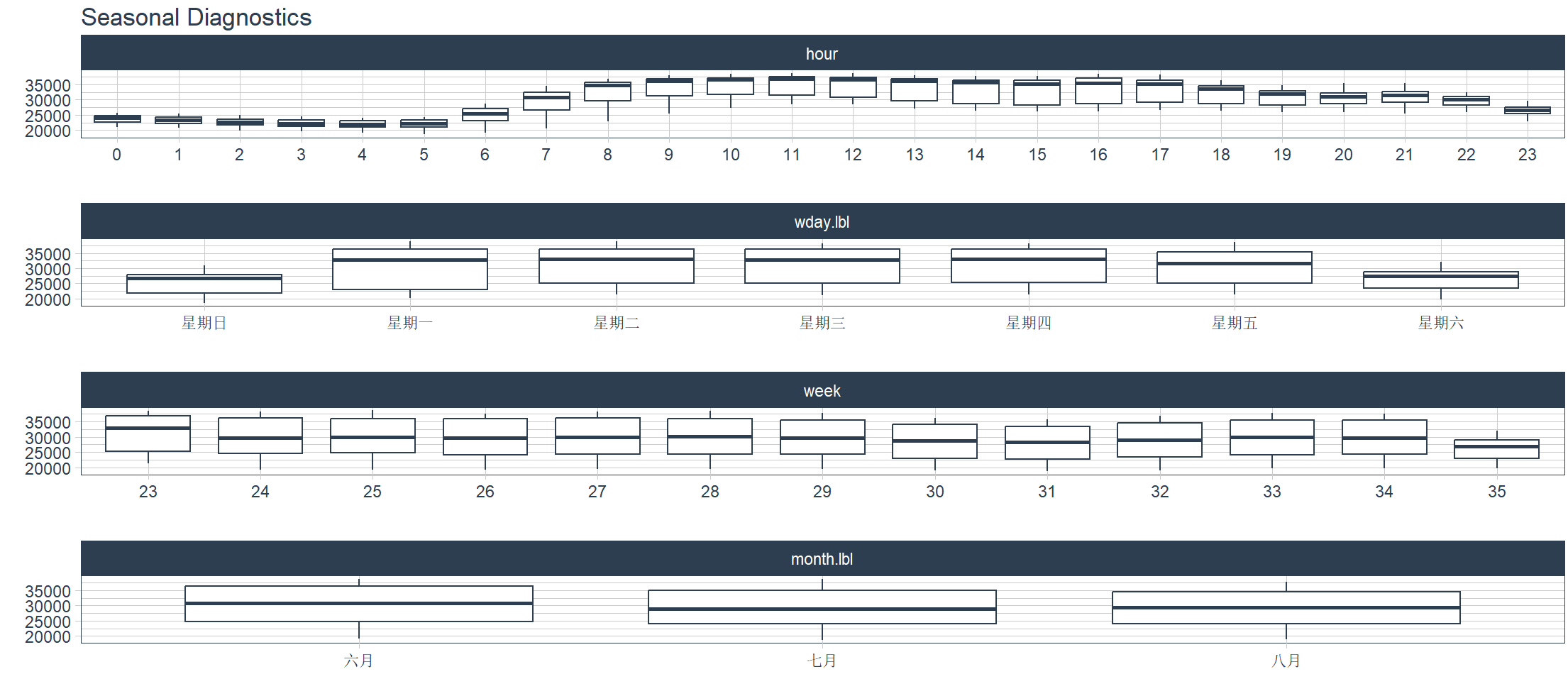
9. Visualizzazione: scomposizione stagionale delle serie temporali
Analisi stagionale, visualizza varie caratteristiche stagionali di una o più serie temporali e genera un dashboard visivo in base alle quattro dimensioni di data, settimana, settimana e mese.
> taylor_30_min %>%
+ plot_seasonal_diagnostics(date, value, .interactive = FALSE)
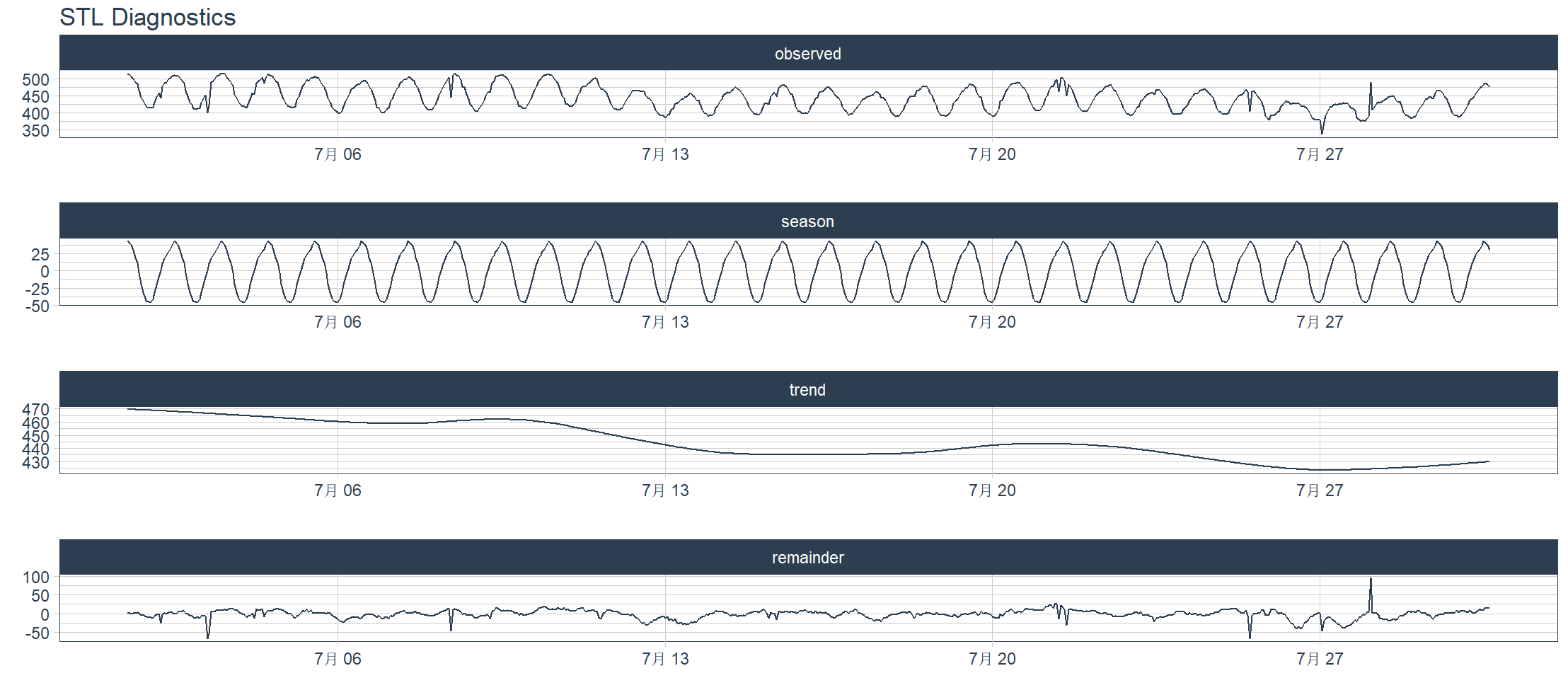
Scomposizione STL, suddivisa per caratteristiche di scomposizione STL, scomposizione della tendenza stagionale basata sulla regressione ponderata locale. La scomposizione STL è un metodo statistico che scompone una serie temporale in tre componenti:
- La componente di tendenza (Trend) è la direzione del cambiamento a lungo termine dei dati, che riflette la tendenza generale regolare.
- Componente stagionale (stagionale) Schemi che si ripetono periodicamente, come fluttuazioni regolari su base settimanale, mensile o annuale
- La componente residua (Remainder) è la fluttuazione casuale o il rumore che rimane dopo aver rimosso trend e stagioni.
L’espressione matematica è:
Osservazioni = Tendenza + Stagione + Resto
> m4_hourly %>%
+ filter(id == "H10") %>%
+ plot_stl_diagnostics(
+ date, value,
+ # Set features to return, desired frequency and trend
+ .feature_set = c("observed", "season", "trend", "remainder"),
+ .frequency = "24 hours",
+ .trend = "1 week",
+ .interactive = FALSE)
frequency = 24 observations per 24 hours
trend = 168 observations per 1 week
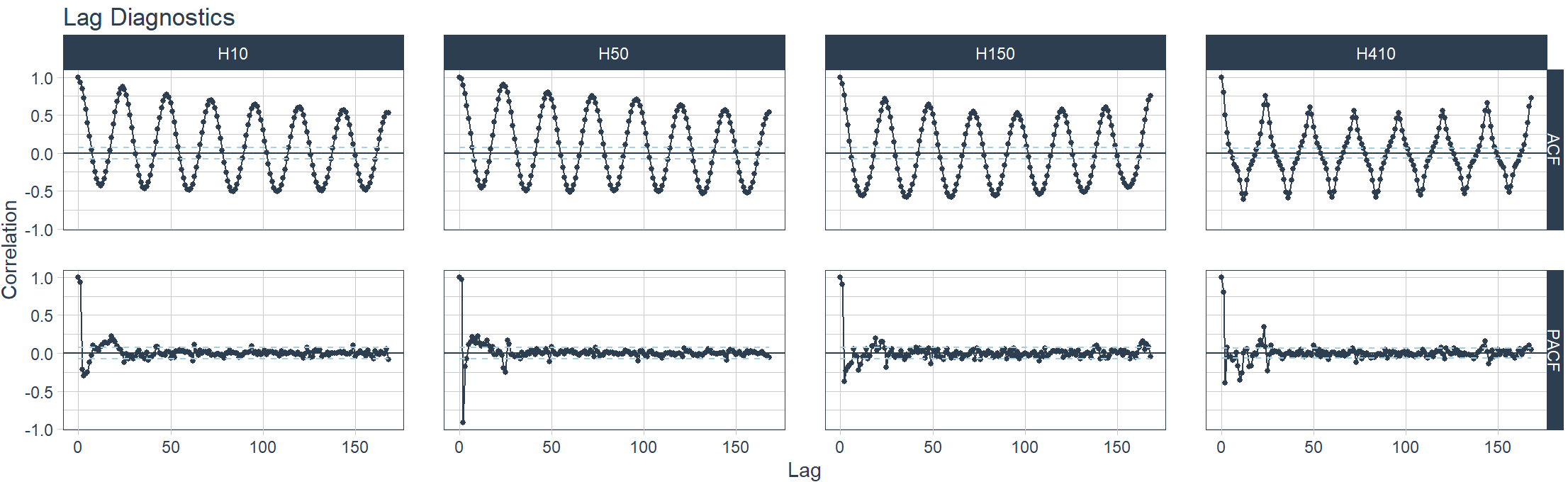
Rilevamento visivo di ACF, PACF e CCF
> m4_hourly %>%
+ group_by(id) %>%
+ plot_acf_diagnostics(
+ date, value, # ACF & PACF
+ .lags = "7 days", # 7-Days of hourly lags
+ .interactive = FALSE
+ )
10. Visualizzazione: ricampionamento di serie temporali
Utilizza il set di dati FANG, che è un set di dati contenente i prezzi azionari storici giornalieri dei titoli tecnologici (“FB”, “AMZN”, “NFLX” e “GOOG”), che copre l’intervallo di tempo dall’inizio del 2013 alla fine del 2016. FANG contiene un “tibble” (casella dati “ordinata”) con 4.032 linee e 8 variabili: simbolo simbolo azionario, apertura alta, chiusura bassa e altre informazioni.
> head(FANG)
# A tibble: 6 × 8
symbol date open high low close volume adjusted
1 FB 2013-01-02 27.4 28.2 27.4 28 69846400 28
2 FB 2013-01-03 27.9 28.5 27.6 27.8 63140600 27.8
3 FB 2013-01-04 28.0 28.9 27.8 28.8 72715400 28.8
4 FB 2013-01-07 28.7 29.8 28.6 29.4 83781800 29.4
5 FB 2013-01-08 29.5 29.6 28.9 29.1 45871300 29.1
6 FB 2013-01-09 29.7 30.6 29.5 30.6 104787700 30.6
# 数据概览
> summary(FANG)
symbol date open high low close
Length:4032 Min. :2013-01-02 Min. : 22.99 Min. : 23.09 Min. : 22.67 Min. : 22.9
Class :character 1st Qu.:2014-01-01 1st Qu.: 106.31 1st Qu.: 107.75 1st Qu.: 104.50 1st Qu.: 106.2
Mode :character Median :2015-01-01 Median : 335.67 Median : 340.68 Median : 331.20 Median : 335.1
Mean :2015-01-01 Mean : 382.70 Mean : 386.38 Mean : 378.67 Mean : 382.6
3rd Qu.:2016-01-01 3rd Qu.: 581.47 3rd Qu.: 585.86 3rd Qu.: 576.52 3rd Qu.: 582.1
Max. :2016-12-30 Max. :1226.80 Max. :1228.88 Max. :1218.60 Max. :1220.2
volume adjusted
Min. : 7900 Min. : 13.14
1st Qu.: 2699875 1st Qu.: 74.82
Median : 7285600 Median :190.75
Mean : 16489749 Mean :297.12
3rd Qu.: 21942350 3rd Qu.:531.37
Max. :365457900 Max. :844.36
Elaborazione dati, ricampionamento
> FB_tbl <- FANG %>%
+ filter(symbol == "FB") %>%
+ select(symbol, date, adjusted)
# 重采样参数配置
> resample_spec <- time_series_cv(
+ FB_tbl,
+ initial = "1 year",
+ assess = "6 weeks",
+ skip = "3 months",
+ lag = "1 month",
+ cumulative = FALSE,
+ slice_limit = 6
+ )
Using date_var: date
# 重采样输出
> resample_spec %>% tk_time_series_cv_plan()
# A tibble: 1,812 × 5
.id .key symbol date adjusted
1 Slice1 training FB 2015-11-19 106.
2 Slice1 training FB 2015-11-20 107.
3 Slice1 training FB 2015-11-23 107.
4 Slice1 training FB 2015-11-24 106.
5 Slice1 training FB 2015-11-25 105.
6 Slice1 training FB 2015-11-27 105.
7 Slice1 training FB 2015-11-30 104.
8 Slice1 training FB 2015-12-01 107.
9 Slice1 training FB 2015-12-02 106.
10 Slice1 training FB 2015-12-03 104.
# ℹ 1,802 more rows
# ℹ Use `print(n = ...)` to see more rows
# 可视化
> resample_spec %>%
+ tk_time_series_cv_plan() %>%
+ plot_time_series_cv_plan(
+ date, adjusted, # date variable and value variable
+ # Additional arguments passed to plot_time_series(),
+ .facet_ncol = 2,
+ .line_alpha = 0.5,
+ .interactive = FALSE
+ )
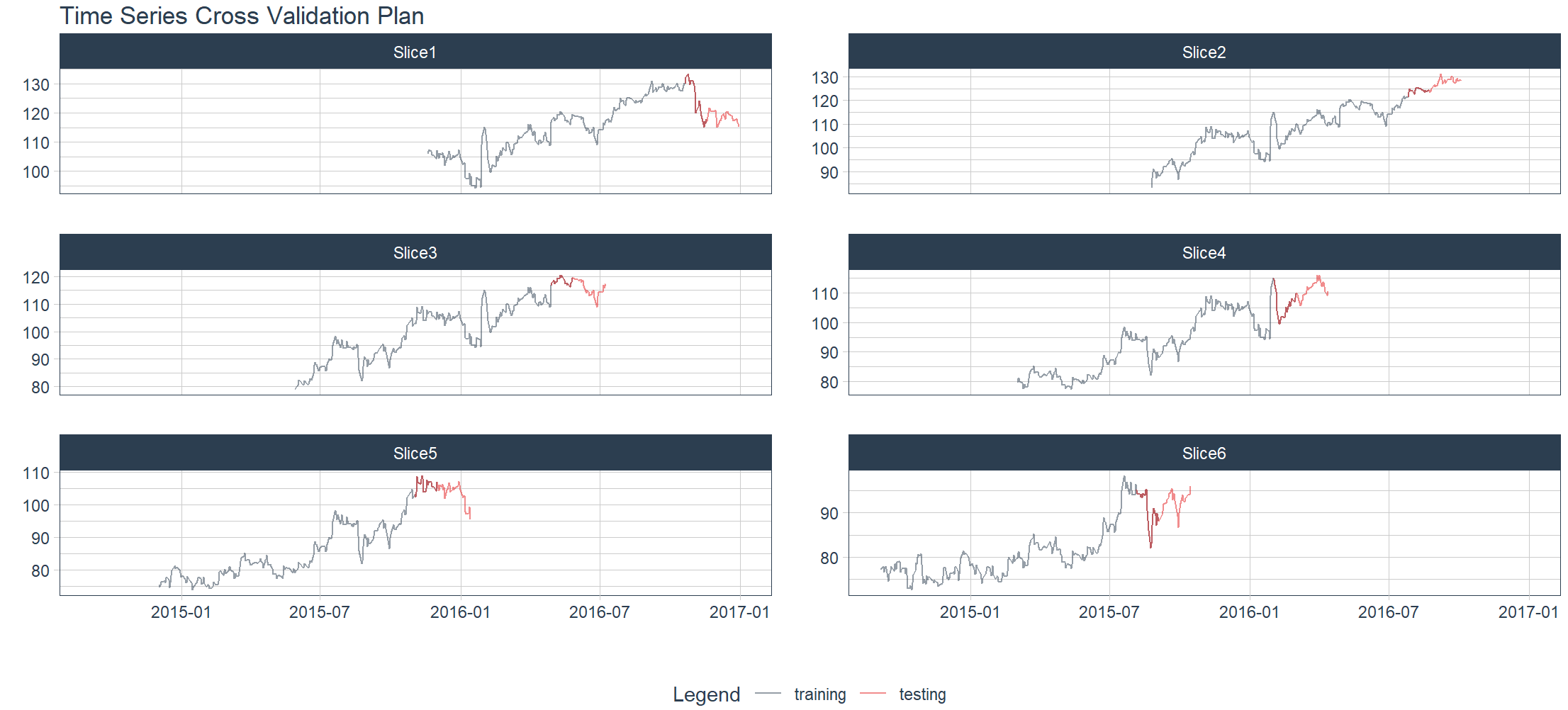
L’esperienza di Timetk è fantastica. Con solo poche righe di codice, puoi vedere chiaramente come osservare i dati delle serie temporali.
Si prega di indicare la fonte in caso di ristampa:
Visualizzazioni dei post: 61
PakarPBN
A Private Blog Network (PBN) is a collection of websites that are controlled by a single individual or organization and used primarily to build backlinks to a “money site” in order to influence its ranking in search engines such as Google. The core idea behind a PBN is based on the importance of backlinks in Google’s ranking algorithm. Since Google views backlinks as signals of authority and trust, some website owners attempt to artificially create these signals through a controlled network of sites.
In a typical PBN setup, the owner acquires expired or aged domains that already have existing authority, backlinks, and history. These domains are rebuilt with new content and hosted separately, often using different IP addresses, hosting providers, themes, and ownership details to make them appear unrelated. Within the content published on these sites, links are strategically placed that point to the main website the owner wants to rank higher. By doing this, the owner attempts to pass link equity (also known as “link juice”) from the PBN sites to the target website.
The purpose of a PBN is to give the impression that the target website is naturally earning links from multiple independent sources. If done effectively, this can temporarily improve keyword rankings, increase organic visibility, and drive more traffic from search results.
